構造は、凝集度が高く、結合度が低い場合に安定する - Larry Constantine
私たちプログラマーは、その仕事において、できる限り良いコードを書きたいと考えます。しかし、「良いコードとは何か」という問いに対して答えるのは、そう簡単ではありません。「良さ」を測るには、「何に対して」という軸が必要であり、その軸は一つではなく、さらには、コードを書いている状況に応じて、大事にすべき軸が変わるということも往々にしてあるからです。そうしたとき、私たちは何らかの尺度でもってコードを測って、そのときのコンテキストにおいて良い落とし所を定めます。
そのようなときに、コードの品質を測る軸としては、有名なものには「凝集性(Cohesion)」と「結合度(Coupling)」があります。ここでは、そのうちの「結合度」を測る指標の一つとして「コナーセンス(Connascence)」を紹介します。
コードの結合度を測る指標
コードの結合度を測る指標としては、『高信頼性ソフトウェア : 複合設計』や『ソフトウェアの複合/構造化設計』などでGlenford Myersによって提唱されたモジュール結合度が有名です。
https://ja.wikipedia.org/wiki/結合度
しかし、モジュール結合度は、現在のプログラミング言語ではすでに問題にしずらかったり、読み替えたりしないと理解が難しい尺度なども混ざっていたりして、今の私たちが尺度にするには少し難しくなってしまっています。
また、他に代表的な結合度の指標としては、『ソフトウェアの構造化設計法』においてEdward Yourdon と Larry Constantineが定義した「主系列からの距離(Distance from the main sequence)」があります。
「主系列からの距離」は、コンポーネントの「不安定性」(「求心性結合(依存入力数、ファンイン)」と「遠心性結合(依存出力数、ファンアウト)」から求められる)と「抽象度」の理想的なバランスからの距離を求めるもので、それによってコンポーネントの依存度や抽象度が適切かが測れます。これは良い指標の一つではありますが、これはこれで、私たちがコードを見ただけで導き出すことは難しいため、コードを書いているときなどに意識する尺度としては少々扱いづらいところもあります。
これらと比べて、「コナーセンス(Connascence)」は、私たちプログラマーがコードを評価したり、リファクタリングする際に比較的意識しやすい尺度が定義されているものであり、その割に知名度が低いと感じるもののため、ここで紹介しようと考えました。
コナーセンス
コナーセンス(Connascence)とは、1992年にMeilir Page-Jones によって考案されたソフトウェア品質指標で、それまでの結合メトリクスを改良して、オブジェクト指向言語用に再構築したものとなります。
https://en.wikipedia.org/wiki/Connascence
コナーセンスという用語は
two components are connascent if a change in one would require the other to be modified in order to maintain the overall correctness of the system (システムの全体的な正しさを維持するために、一方の変更が他方の変更を必要とする場合、2つのコンポーネントはコナーセントである)
という文章からきており、コナーセント(connascent)とは「con- + nascent (「共に」「出現する」)という意味になります。
コナーセンスの特徴
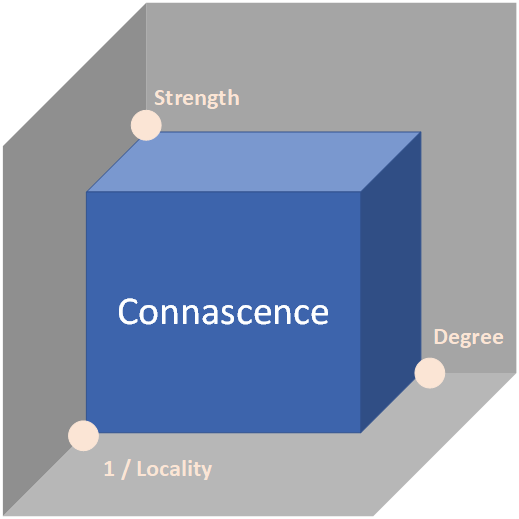
コナーセンスでは、以下の3つの尺度(次元)を用いて、コードの品質を評価します。
引用: https://programhappy.net/2020/06/22/connascence-why-is-it-so-important/
度合い(Degree)
どれだけ結合されているか。結合の度合いが強い(高い)ほど、変更の難易度およびコストが高くなる
強度(Strength)
コナーセンスには種類(後述)に応じて強度があり、強いコナーセンスほど変更の難易度とコストが高くなる
距離(Locality)
関係する要素がどれだけ近いか。同じ強度と度合いのコナーセンスでも、関係する要素が離れているほど、変更の難易度とコストが高くなる
結合といって一般に想像される度合い(degree)に加えて、強度(strength)と距離(locality)という次元を持たせているところが、コナーセンスの大きな特徴となります。
コナーセンスを数値として計算する場合には、以下のような式で数値を検出します。
Strength x Degree / Locality
コナーセンスの種類
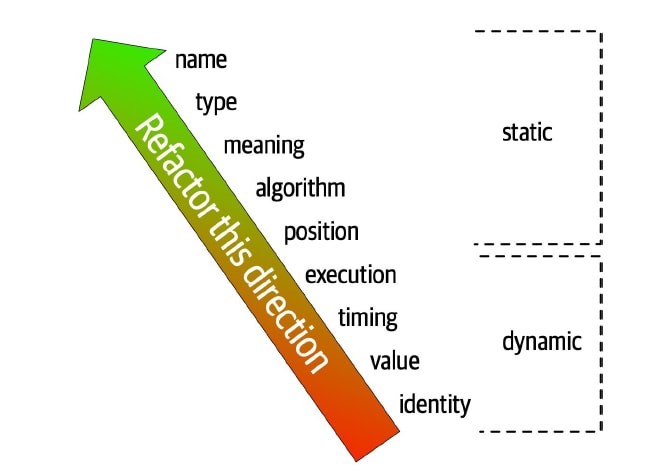
強度のところで触れたコナーセンスの種類には、次のようなものがあります。これらは、コンポーネントが何によって結びついているかに従った分類となっています。
- 静的なコナーセンス: コードレベルで生じる結びつき
- 名前のコナーセンス Connascence of Name (CoN)
- 他方のコンポーネントが持つ要素の名前(メソッド名など)を参照している状態
- 型のコナーセンス Connascence of Type (CoT)
- 他方のコンポーネントが持つ要素の型を知っている状態
- 意味のコナーセンス Connascence of Meaning (CoM)
- 複数のコンポーネントが特定の値の意味を共有している状態
- 位置のコナーセンス Connascence of Position (CoP)
- メソッドのパラメータ順序などを知っている必要がある状態
- アルゴリズムのコナーセンス Connascence of Algorithm (CoA)
- 名前のコナーセンス Connascence of Name (CoN)
- 動的なコナーセンス: 実行時に生じる結びつき
これらは、上のコナーセンスほど結びつきの強度が弱く、下にいくほど強度が強い、という関係になっており、できるだけ弱いコナーセンスに向けてリファクタリングするのが良いとされています。
参考 https://dev.to/edisonnpebojot/architecting-modules-for-software-modularity-part-2-3bpc
コナーセンスをどのように意識するか
ここからは、具体的なコードを見ながら、コードを書くときにどのようにコナーセンスを意識するかの例を見ていきましょう。
例1: 意味のコナーセンスを名前のコナーセンスに変換して、コナーセンス強度を下げる
たとえば、以下のようなコードがあったとします。
class Item … def price(tax_included=false) if tax_included price * TAX else price end end … end
この Item#price を利用するには、引数に渡す true や false の意味を利用者側のコンポーネントが知っている必要があります。この状態は、意味のコナーセンスが生じている状態といえます。
これを、名前を知っていればメソッドを利用できる状態にしましょう。
class Item … def price_including_tax price * TAX end … end
これで、メソッド名さえ知っていればコンポーネントを利用できるようになりました。
例2: 実行順序のコナーセンス→位置のコナーセンス→名前のコナーセンス
たとえば、以下のようなコードがあったとします。
email = Mail.new email.recipient "foo@example.com" email.sender "me@example.com" email.subject "Hi" email.body "Hello" email.send
このとき、たとえば Mail#recipient や Mail#subject といったメソッドは Mail#send の手前で呼び出す必要があるとします。この場合には、 Mail と利用者側のコンポーネントには実行順序のコナーセンスが生じている状態といえます。
これは、手続きが個々のメソッドに分かれていることが原因ですので、まずは手続きをひとまとめにしましょう。
class Mail ... def send(from, to, subject, body) ... end end
これで、実行順序を気をつけなくてもメソッドを利用できるようにはなりました。
email.send("foo@example.com", "me@example.com", "Hi", "Hello")
しかし、今度は引数の順序を知らなければコンポーネントを正しく利用できません。この状態は、 Mailと利用者側のコンポーネントには位置のコナーセンスが生じている状態といえます。
次は、このメソッドにパラメータ引数を導入して、位置を知らなくてもメソッドを利用できるようにしましょう。
class Mail ... def send(from:, to:, subject:, body:) ... end end
これで、位置を知らなくてもメソッドを利用できるようになりました。
email.send( from: "foo@example.com", to: "me@example.com", subject: "Hi", body: "Hello" )
この状態は、メソッド名とパラメータ名を知っていればメソッドを利用できるので、名前のコナーセンスがある状態といえます。
コナーセンスを設計のものさしに使う
どうだったでしょうか。もちろん、コナーセンスを知らなくても、自然と上記のような設計判断をするよという方もいるとは思います。ですが、コナーセンスの概念を用いることで、上記のような判断をある程度しっかりとした軸をもって進められそうな感じがしないでしょうか。少なくともモジュール結合度よりは今のコンテキストに素直にのせて評価しやすい指標ではないかなと考えます。
また、上記の例では、コナーセンスの種類(強度)だけにフォーカスしていましたが、ここに距離や度合いの観点も踏まえて考えると、さらにより良い判断のヒントが得られるだろうと考えています。
たとえば、位置のコナーセンスが生じていたとしても、2個の引数の場合と7個の引数の場合とでは、その度合いが異ります。あるいは、メソッドが同じファイル内からしか利用できない場合と、自分たちがメンテナンスしていないコードから利用される場合とでは、その距離が異なります。こうしたことを踏まえて、じゃあどのコナーセンスで十分としようか、といった具合です。
コナーセンスは他の尺度と比べるとだいぶマイナーなコンセプトで、日本語書籍で扱っているのも今のところは『Adaptive Code ~ C#実践開発手法 第2版』 (日経BP)くらい、英語圏でもそこまで流通はしていなさそうです。僕が調べた中では、RubyistにはおなじみのJim Weirichが2012〜2013年あたりに講演している内容がもっとも充実していると感じました。よければ時間のあるときにでも眺めてみてもらえたら嬉しいです。
以上で、簡単なコナーセンスの紹介を終わります。この記事が、より良い設計のヒントになれば幸いです。
参考文献
- https://en.wikipedia.org/wiki/Connascence
- Gary Maclean Hall『Adaptive Code ~ C#実践開発手法 第2版』 (日経BP)
- YOW! 2012 Jim Weirich - Connascence Examined

What Every Programmer Should Know About Object-Oriented Design
- 作者:Page-Jones, Meilir
- 発売日: 1996/08/01
- メディア: ハードカバー

- 作者:Gary McLean Hall
- 発売日: 2018/06/05
- メディア: Kindle版